Main Contributions
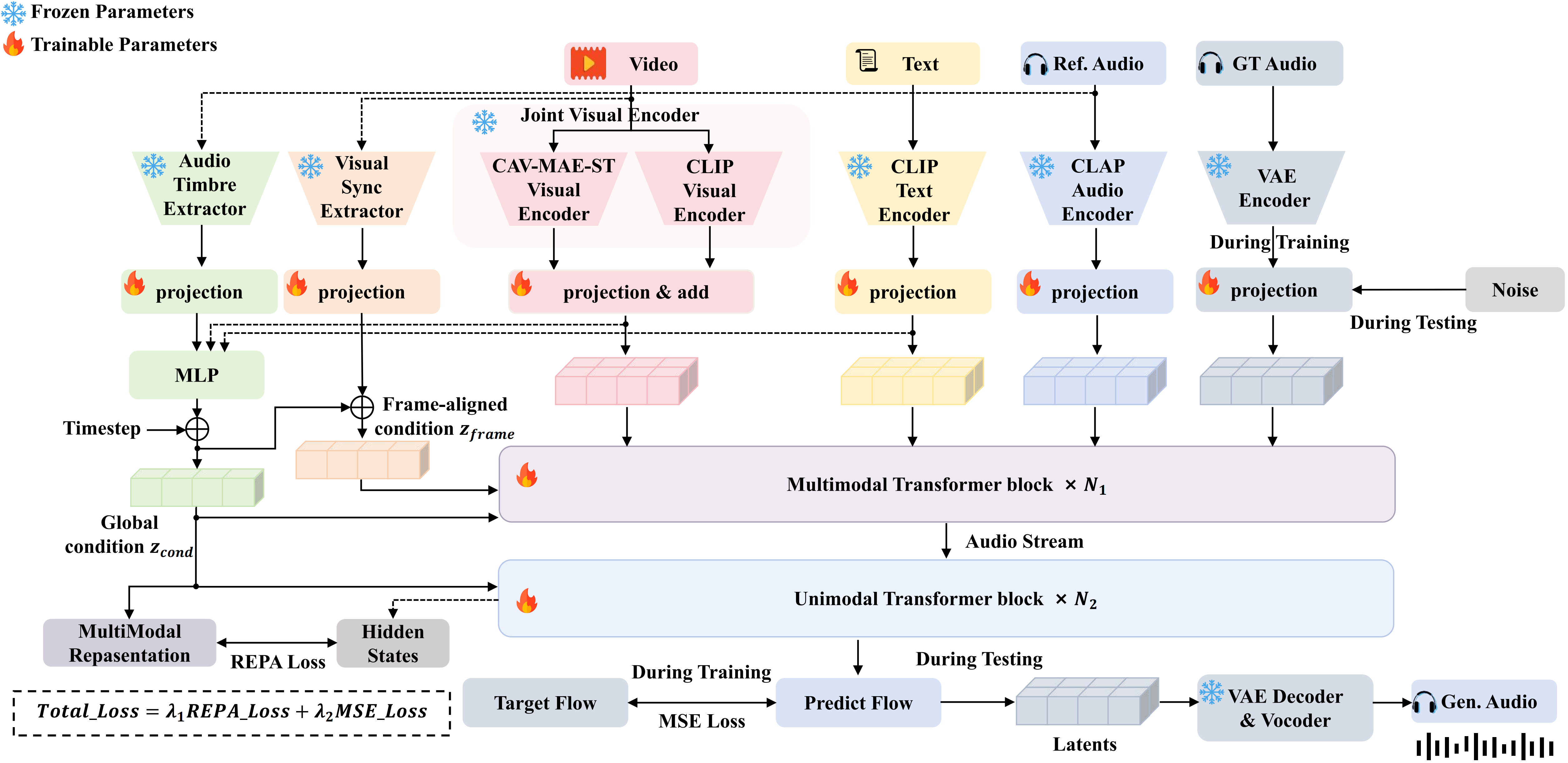
We propose ControlFoley, a unified and controllable multimodal V2A framework that enables precise control across video, text and reference audio. The key contributions of ControlFoley are as follows.
• Joint Visual Encoding for Robust Multimodal Control.
We propose a dual-branch visual encoding paradigm that combines CLIP and CAV-MAE-ST representations, capturing both vision-language and audio-visual correlations to mitigate modality conflict and improve textual controllability.
• Timbre-Focused Reference Audio Control.
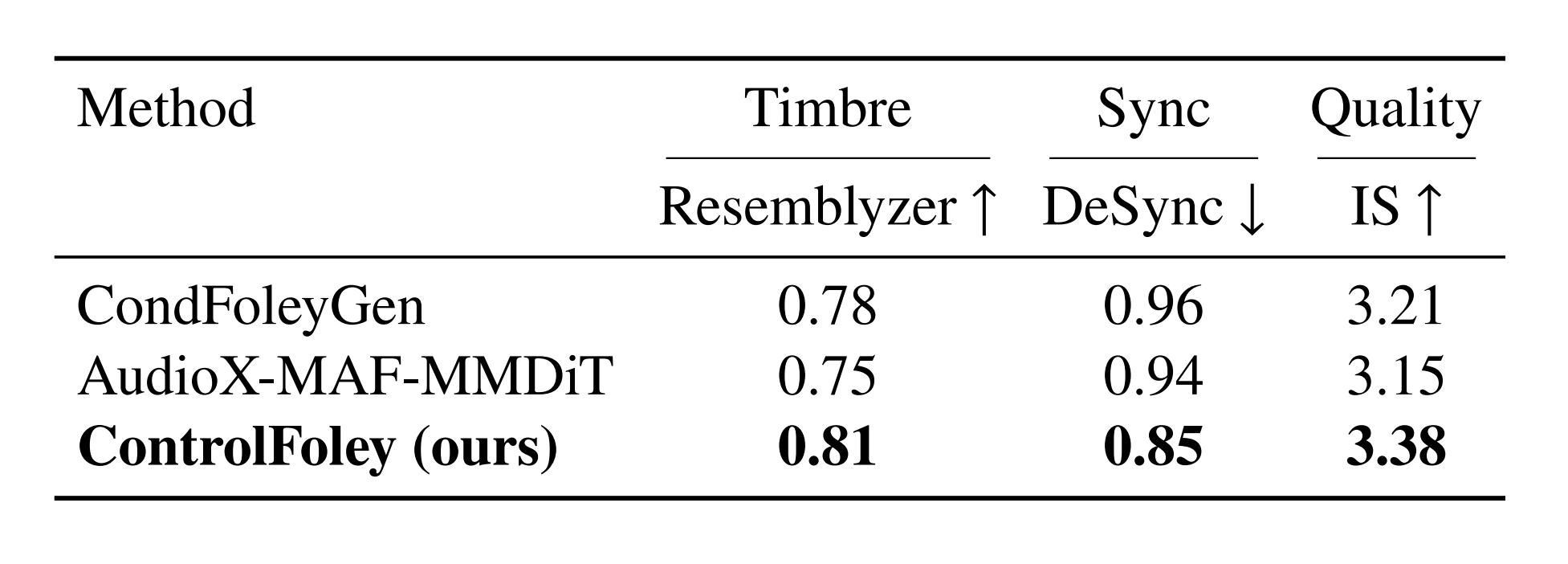
We design a reference audio control mechanism that suppresses temporal information and extracts global timbre representations, enabling precise acoustic style control without interfering with video-driven synchronization.
• Modality-Robust Training with Unified Alignment.
We introduce an all-modality dropout strategy and a unified REPA alignment objective, improving robustness under varying modality combinations and enhancing multimodal consistency.
• VGGSound-TVC Benchmark.
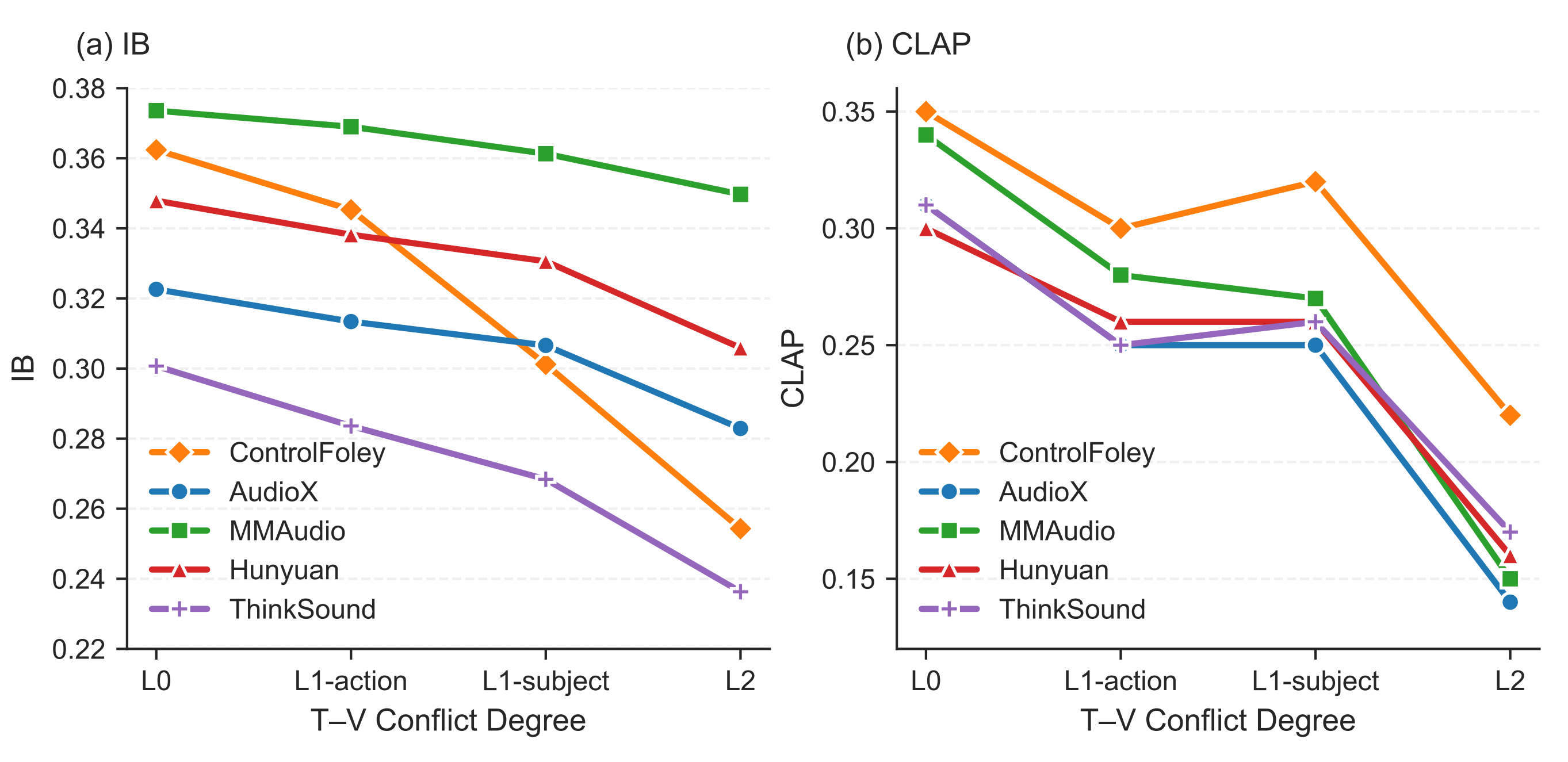
We construct a benchmark for evaluating textual controllability under visual-text semantic conflicts, providing a standardized testbed for TC-V2A.
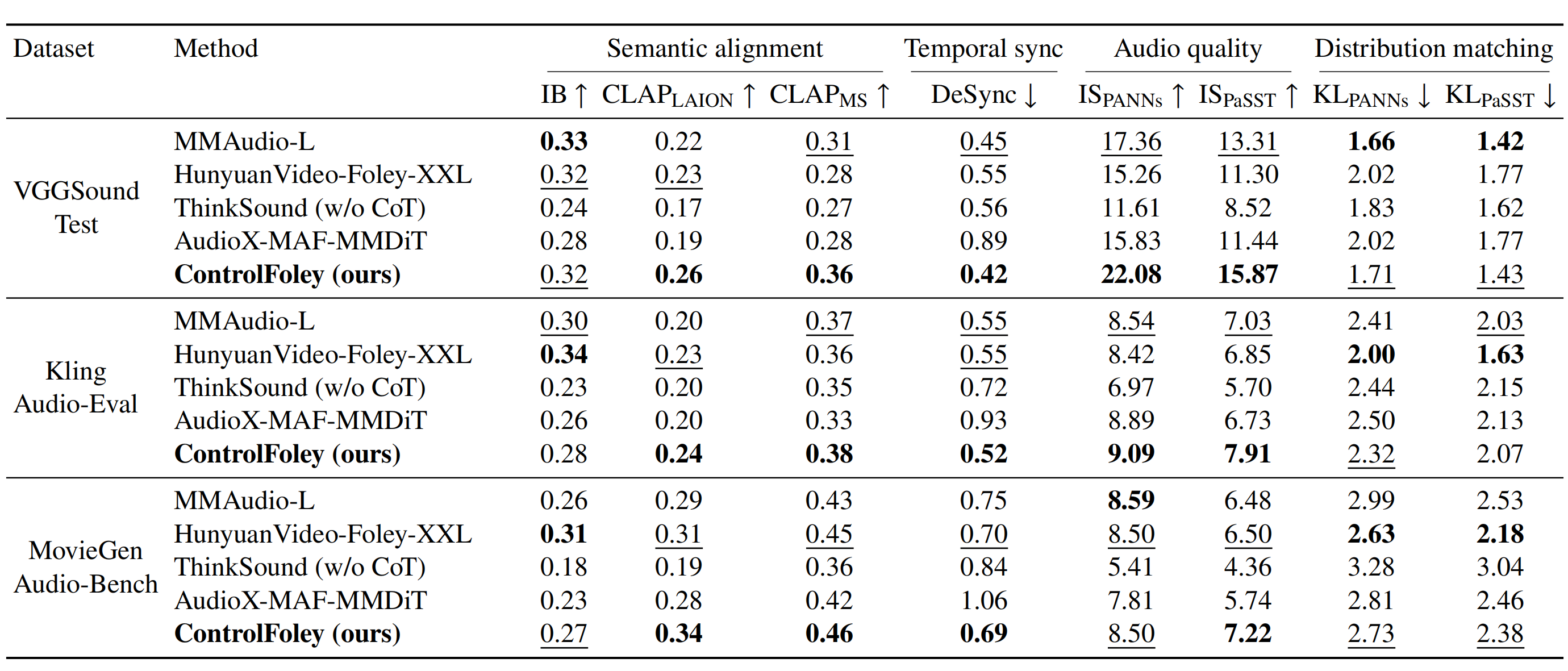
Extensive experiments demonstrate that ControlFoley achieves state-of-the-art performance across multiple V2A tasks, including TV2A, TC-V2A, and AC-V2A, while significantly improving controllability and robustness under challenging multimodal conditions.